


The Llama herd under the hood: 6 key research decisions decoded

Hi, I'm Meghana 👋, welcome to the very first edition of The Next Token, my newsletter distilling AI research and decoding the tech behind the buzz. Here’s why I started the series.
For the launch, we're dissecting Llama 4. We'll explore the core strategies that power its capabilities – from its unique hybrid positional encoding and attention scaling techniques to its training and post-training strategies.
Last week:
Llama 4 drops.
Everyone loses their mind over the context window (me too!!)
Someone points out that there was data contamination, resulting in inflated results
Drama everywhere
Meghana decides to write a blog post
In this post, I'll dissect the key technical decisions that enable Llama 4's capabilities, examining how Meta's research team solved fundamental challenges in scaling context, multimodal processing, and alignment.
First, the basics - Three models, trained with FP8 precision. All MoE. All natively multimodal and multilingual (200 languages). “Scout” with int4 quantization can fit into a single H100 GPU. “Maverick” claims to have best-in-class image grounding when still being able to fit in a single H100 node(for context, Deepseek-R1 needs 2 H100 nodes)
My analysis focuses on six critical decisions that collectively enable Llama 4's capabilities: (1) the hybrid positional encoding strategy, (2) attention scaling techniques, (3) pretraining innovations, (4) the co-distillation approach, (5) scaled post-training methodology, and (6) safety testing frameworks.
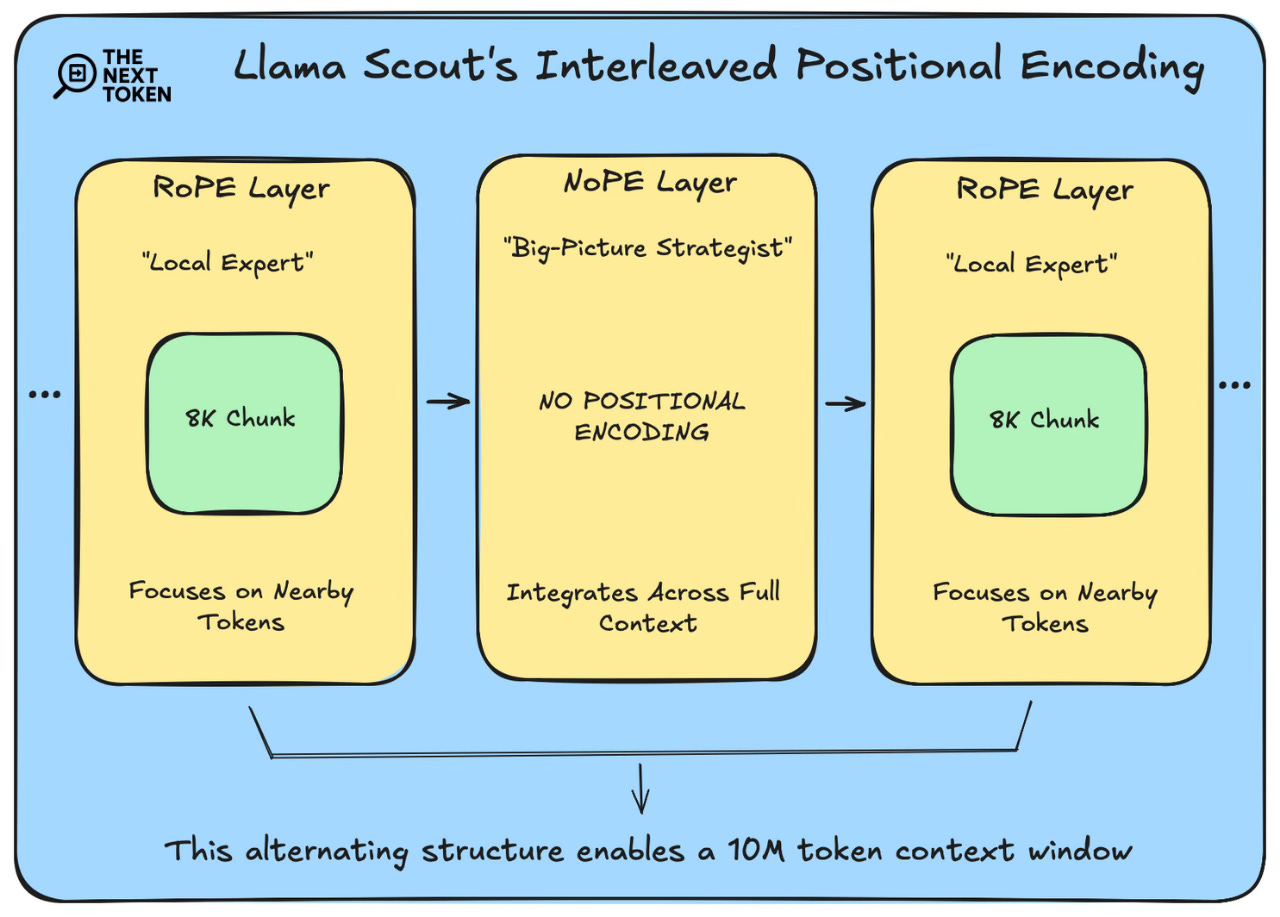
1. Used RoPE + NoPE hybrid to increase context window
The 10 million token context window of Llama 4 Scout represents a watershed moment for open-source models, setting a new record that dramatically exceeds previous capabilities. While proprietary models like Google's Gemini 2.5 Pro (1M tokens currently in production, with 10M only demonstrated in research settings) and Anthropic's Claude 3.7 (200K tokens) have pushed boundaries, Scout is the first open-source model to reach the 10M mark.
Problem
Traditional positional embeddings, like absolute PE (think GPT-3, which uses learned APE), struggle to generalize beyond their training sequence length. Even relative embeddings like RoPE, while better, can falter during downstream tasks requiring significant length extrapolation.Fix: An Elegant Interleaving
RoPE (Rotary Positional Encoding) Layers - The Local Expert
Llama 4 uses chunked attention (8k token windows) to focus on nearby context.
NoPE (No Positional Encoding) Layers - The Big-Picture Strategist
These NoPE layers rely purely on the inherent causality of the attention mechanism (seeing only past tokens) to understand sequence order implicitly. This clever trick reduces computational overhead while forcing the model to aggregate information over much longer distances.
Interleaving these layers allows Llama Scout to scale its context length to 10M tokens.
2. Mitigated attention fading with inference time attention scaling
Problem
In standard SoftMax, as the sequence length (n) grows, the denominator (sum of all exponentiated scores) increases rapidly. This can 'drown out' individual high scores, leading to a flatter, less discriminative attention distribution – the model essentially loses focus(attention fading).SSMax re-engineers softmax to explicitly account for sequence length n, preventing attention decay.
By scaling the exponent with s logn, both the numerator and denominator grow proportionally to n.
This counteracts the "flattening" effect of long sequences, keeping attention scores sharp.

3. Used MetaP, Early Fusion, and Query-Key Normalization in Pretraining
MetaP
Training giant models like Llama 4 requires tuning thousands of hyperparameters (learning rates, initialization scales) by layer—a tedious, error-prone process.
MetaP automatically finds optimal settings that:
✅ Transfer across different model sizes (109B → 2T)
✅ Adapt to batch sizes/training tokens
Early Fusion
All modalities(text, images, videos) are combined at the input level itself before being processed by the model.
This encourages the model to learn joint representations from the get-go, enabling more seamless and potentially deeper cross-modal reasoning and generation. Meta talked about this in detail in its Chameleon paper.
Query-Key Normalization
Given Llama 4 employs early fusion, managing potential training instabilities becomes crucial. One key technique for this, introduced in Meta's earlier Chameleon paper to address this very issue, is Query-Key Normalization. While the Llama 4 report doesn't explicitly confirm its use, I think understanding QK-Norm is relevant.
The shared weights in early fusion force the model to handle diverse data types. The model subtly learns to use the magnitude of inputs to the softmax as a way to help differentiate processing for different modalities. The translation invariance property of softmax (softmax(z) = softmax(z + c)) means there's no inherent penalty for this increase in magnitude. Over long training runs, this leads to a slow drift where magnitudes grow until they exceed the limits of fp8, causing numerical instability and divergence. QK-Norm directly counters this specific instability by applying Layer Normalization independently to the Query (Q) and Key (K) vectors before the attention scores are computed, thereby explicitly constraining the magnitude of the vectors that determine the inputs to the problematic attention softmax.
4. Used co-distillation with Llama Behemoth as a teacher
Problems with traditional knowledge distillation
Computational inefficiency: Training the massive teacher (Llama Behemoth) is already astronomically expensive. Traditional distillation then requires running this giant model repeatedly just to generate targets for the student(Llama Maverick), adding significant compute overhead.
Static loss functions: Traditional approaches use fixed weights that can't adapt to the changing reliability of teacher predictions throughout training
Fix: Co-distillation
✅ Addressing computational inefficiency: Meta "amortizes the computational cost" by:
Training teacher + student together simultaneously instead of sequentially
Reusing each teacher forward pass for dual purposes:
Updating teacher parameters
Generating soft targets for the student
✅ Addressing static loss functions: The blog mentions a "novel distillation loss function that dynamically weights soft and hard targets." In practice, this means:
Rather than using fixed weighting, the system automatically adjusts the relative importance of soft vs. hard targets as training progresses.
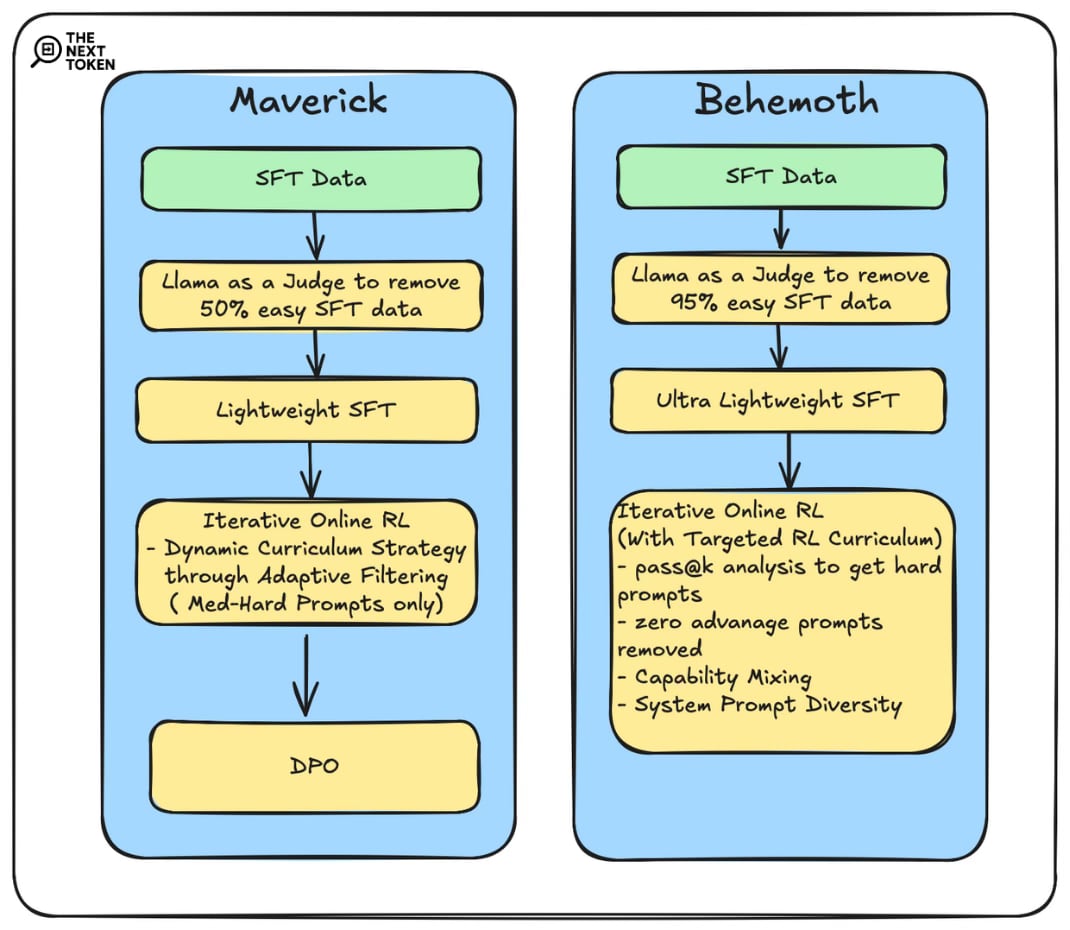
5. Post-trained with lightweight SFT -> RL -> DPO
Llama Maverick
Initial Grounding (Lightweight SFT): Used Llama 3 models as judges to identify and remove over 50% of data deemed "easy." This aggressive filtering focuses the initial SFT stage purely on higher-quality, more challenging examples.
This means that data volume alone in SFT is less important than data quality and difficulty. Focusing compute on examples that actually teach the model something new is far more efficient.
Capability Enhancement (Online RL): They implemented a continuous online RL strategy. This involved alternating between training the model and using that updated model to filter the prompt pool. At each filtering stage, they retained only medium-to-hard difficulty prompts for the next round of RL training. This adaptive filtering, focusing on progressively harder examples relevant to the model's current state, acted as a dynamic curriculum.
DPO: Improved model response quality, achieving a good balance between the model’s intelligence and conversational abilities.
Llama Behemoth
Ultra Lightweight SFT: The data filtering here was even more extreme. Meta reports pruning 95% of the initial SFT data. In addition to the reason we discussed above, models of Behemoth's size are very prone to memorization rather than generalize from training data, especially during the more focused SFT phase. So a hyper-focused SFT helps mitigate that.
Targeted RL Curriculum: Behemoth's RL recipe was also tailored:
Hard Prompt Mining: They used pass@k analysis with the current policy model to specifically identify difficult prompts where the model struggles. This creates a curriculum of increasing hardness.
Dynamic Advantage Filtering: During RL training, they dynamically filtered out prompts where the model showed zero “advantage.” Filtering zero-advantage prompts removes examples that are either too easy (no improvement needed) or where the reward signal isn't strong enough to guide learning effectively, again optimizing the use of computational resources for impactful updates.
Capability Mixing: Training batches were deliberately constructed with mixed prompts covering multiple capabilities (e.g., math, reasoning, coding). This is crucial to prevent "catastrophic forgetting" or "alignment tax," where fine-tuning heavily on one skill degrades others.
System Prompt Diversity: Finally, sampling from a variety of system instructions during RL. This ensures the model doesn't just become good at specific tasks but retains robust instruction-following capabilities across different domains and interaction styles, maintaining its versatility despite the focused RL training.
To sum up the key insights from post-training of the Llama 4 models:
Aggressive data curation is paramount
Sophisticated curriculum strategies drive learning
Post-training requires scale-specific tuning
The stark difference in SFT data pruning (50% Maverick vs. 95% Behemoth) proves recipes aren't one-size-fits-all.
Maintaining capability breadth boosts performance in math, reasoning and coding
6. Red-teamed with “GOAT”
Now, for a section, I absolutely couldn't skip, given my work in model safety and alignment: Red-Teaming. Meta mentions their development of GOAT (Generative Offensive Agent Testing), a system designed to simulate realistic, multi-turn jailbreaking attempts against their models.
The lack of specifics leaves me (and likely many others) very curious and eager for more. I'll be keeping a close eye out for any dedicated paper or technical deep dive Meta might release on GOAT in the future.
In conclusion
While the jury’s still out on data contamination and benchmark integrity, Meta’s engineering innovations themselves are worth studying. As we've done here, peeling back the layers reveals a suite of clever solutions to hard problems in large-scale AI.
With that, thanks for reading! Stay tuned as we continue to distill and decode the next big developments here at The Next Token.
I appreciate you spending your time here!
Subscribe to The Next Token to get notified about my new posts.
Let me know your thoughts below – What resonated? What could be clearer?