

Hi, I'm Meghana 👋, welcome to the second edition of The Next Token, my newsletter distilling AI research and decoding the tech behind the buzz. Here’s why I started the series.
What transforms a pretrained language model into a powerful reasoning engine? The answer lies in post-training—the crucial phase where models learn to solve math problems, write correct code, and follow complex instructions. I recently went down a bit of a rabbit hole exploring how different models tackle this, and thought it was a good idea to compile everything in one place. In this blog, I break down and compare the post-training strategies of top reasoning models: Kimi 1.5, Qwen 2.5, DeepSeek R1/Zero, OpenReasoner-Zero, QwQ 32B, and Phi-4.
We'll focus on their approaches to:
SFT
Reward Modeling (rule-based vs learned)
Reinforcement Learning (design choices, objectives, algorithms)
Data Curation (source, quality filters, and control)

Let’s dive into how these models go from raw potential to skilled reasoning agents—step by step.
🔎Model-by-Model Post-Training Breakdown
DeepSeek-R1-Zero
DeepSeek took a bold approach by skipping SFT entirely, instead letting the model develop reasoning capabilities through pure reinforcement learning. They wanted to see if the model could figure things out on its own.
RL
Used the GRPO algorithm(We won’t dive deep into this here. There are already a lot of resources covering this!)
Reward Modeling: Rule-Based Rewards
Why Rule-Based? Instead of training another complex model just to judge the main model's answers (which is common), the DeepSeek team opted for straightforward, rule-based rewards. Why?
Avoiding "Reward Hacking": Trained reward models can sometimes be tricked. Models might figure out how to get a high "reward score" without actually doing the task well – basically, gaming the system. Rule-based rewards are harder to cheat.
Simplicity & Efficiency: Training and constantly updating a separate reward model takes extra time, resources, and makes the whole training pipeline more complicated. Rules are simpler!
What Rules Did They Use?
Accuracy Rewards: Did the model get the right answer? This was checked automatically.
Math Example: The model had to put its final answer in a specific format (like \boxed{123}). Easy for a script to check if it's correct.
Coding Example (LeetCode): They used a compiler to run the model's code against test cases – pass or fail, clear feedback.
Format Rewards: Did the model show its work correctly? It got rewarded for putting its "thinking process" neatly between <think> and </think> tags. This helped structure the reasoning.
Training Template & Philosophy
Minimal Constraints: The main rule was just that <think> tag structure. They didn't force the model to use specific thinking steps.
No Content Bias: They carefully avoided pushing the model towards certain problem-solving methods (like telling it "you must reflect here").
The Goal: The idea was to just set up the basic rules (correctness, format) and then sit back and watch how the model naturally learned to reason and solve problems on its own through the RL process. They wanted to see genuine learning, and not just mimicking.
Emergent Reasoning Behaviors - The “Aha” Moment
Here's where things get really interesting with DeepSeek-R1-Zero's approach. A key finding was watching advanced reasoning skills pop up spontaneously without the team explicitly training the model for them.
What Emerged Naturally? As the model interacted with the RL environment, simply trying to optimize for those rule-based rewards (getting the right answer in the right format), complex behaviors started showing up on their own. These included things like:
Reflection: The model actually started revisiting and rethinking its previous steps – like catching its own potential mistakes.
Exploration: It began trying out different ways to tackle a problem instead of just sticking to one path.
Why This Matters: These weren't behaviours they programmed in; they grew organically out of the learning process. And the result? This natural development gave DeepSeek-R1-Zero a significant boost in its reasoning chops. It essentially learned how to reason better, not just follow specific reasoning patterns.
Deepseek-R1
Stage 1: Cold Start SFT
The Problem: While innovative, DeepSeek-R1-Zero had some rough edges – particularly issues with readability and sometimes mixing languages within its reasoning. Plus, they wanted a more reliable way to teach the model the desired format for showing its reasoning steps.
The Solution: SFT! They decided an initial Supervised Fine-Tuning (SFT) phase was needed.
The Data: They collected thousands of "cold start" data points. This wasn't just random data; it was specifically generated (by prompting Deepseek V3) to include elements like reflection and verification steps within the reasoning, aiming to directly address R1-Zero's shortcomings and enforce a cleaner output format.
The Goal: Use this high-quality, targeted SFT data to give DeepSeek-R1 a much better starting point, especially regarding structured reasoning and language consistency, before hitting the RL stages.
Stage 2: First RL Round (Sharpening Reasoning & Language)
Focus: With the format basics improved by SFT, this first RL phase zoomed in on core reasoning tasks – think math, coding, and logical puzzles.
Tackling Language Mixing: They introduced a "language consistency reward" during RL to address language mixing. This reward basically checked the model's Chain-of-Thought (CoT) reasoning and gave it points based on the proportion of words matching the target language (e.g., ensuring an English prompt gets English reasoning).
The Reward Signal: The final reward guiding the model in this stage was a sum of:
Accuracy Reward: Still using the reliable rule-based checks (like in R1-Zero) for correctness in math/code.
Language Consistency Reward: The new reward component to discourage language mixing.
Stage 3: Another Round of SFT
New Focus: The spotlight shifted towards more general-purpose tasks like writing and role-playing, while still refining reasoning.
Data Collection Strategy (Two Prongs):
Reasoning Data (Refined & Expanded):
They collected initial reasoning examples from the Stage 2 RL model using rejection sampling(filtering out those with language mixing, overly long paragraphs, or messy code blocks).
They then expanded this reasoning dataset by incorporating additional data. A key feature of this expansion was how some of this new data was evaluated:
For complex reasoning problems where simple rule-based checks weren't sufficient (unlike the previous stage which relied mainly on rule-based accuracy and language consistency checks), they used a learned reward model. This involved feeding both the ground-truth answer and the model's prediction into DeepSeek-V3 to get correctness.
Scale: Resulted in about 600,000 reasoning data points for this SFT stage.
Non-Reasoning Data:
They reused prompts from the training data of their base model, DeepSeek-V3.
For tasks where thinking steps might be helpful (even general ones), they prompted DeepSeek-V3 to generate Chain-of-Thought reasoning to accompany the prompt/answer pair.
However, they were pragmatic: for simple prompts like just "hello", no CoT was forced.
Stage 4: Secondary RL Stage (Helpfulness, Harmlessness & Polish)
The Goal: This final RL stage aimed to polish the model into a well-rounded assistant, focusing on improving helpfulness and harmlessness while also continuing to refine the reasoning capabilities from earlier.
Training Approach (Dual Strategy):
Reasoning Training: For tasks like math, code, and logic, they stuck with the tried-and-true DeepSeek-R1-Zero methodology using rule-based rewards for accuracy.
General Data Training: For everything else (writing, role-play, general queries), they used trained reward models.
Specific Objectives within General Training:
Helpfulness Objective: The reward model focused only on the final answer. The idea was to judge the utility and relevance of the output without focusing on intermediate reasoning steps.
Harmlessness Objective: Here the reward model evaluated the entire response (including the reasoning/CoT).
Stage 5: Distillation (Sharing the Knowledge)
Goal: Take the highly capable (but large) DeepSeek-R1 and transfer its reasoning abilities to smaller, more efficient models.
Process:
They generated a large SFT dataset (around 800,000 data points) using outputs from the fully trained DeepSeek-R1.
This dataset was then used for SFT on the smaller target models.
They did not do any RL on the smaller models. But, applying RL tuning could further refine and boost the performance of these smaller models
OpenReasoner Zero
Next up is OpenReasoner Zero (ORZ), which introduced the term 'Reasoner-Zero training' for its philosophy. Similar in spirit to DeepSeek-R1-Zero's method, this means they dive straight into large-scale Reinforcement Learning (RL) to build reasoning capabilities without doing SFT first.
RL
Data Curation
Need for Quality: The team emphasizes that high-quality training data is absolutely crucial for making this "Reasoner-Zero" approach work at scale.
Data Sources: They gathered a diverse collection of public data, including problems from AIME, MATH dataset, Numina-Math collection, Tulu3 MATH, OpenR1-Math-220k, etc.
Targeted Difficulty: AMC, AIME, general Math Olympiads, and AoPS forum problems were classified as their "difficult level" prompts.
Filtering Strategy (Multi-Step):
Evaluability Filter: Like the DeepSeek models which also relied heavily on rule-based rewards, ORZ filtered out problems that are hard to grade automatically with simple rules. Mathematical proofs, for instance, were excluded because their correctness isn't just a final numerical answer.
Model-Based Difficulty Filter: They used a model to estimate the "pass rate" for each potential training problem. Problems that were too easy (high pass rate) or seemingly impossible (zero pass rate) were removed.
Resulting Dataset: This curation process yielded a dataset of 129,000 problems.
"Hard Prompt" Mining & Fine-tuning: They added a clever final step:
During an initial training run (1100 steps) on the 129k dataset using their 32B parameter model, they identified the toughest problems – specifically, about 13,000 prompts where the model got the answer right fewer than 4 times out of 64 attempts.
These identified "hard prompts" were then used exclusively in a final, short training phase (100 steps).
Reward Function: Simple, Strict Accuracy
Rule-Based Rewards: Like DeepSeek-R1-Zero, ORZ sticks to rule-based rewards.
Accuracy Only: Their reward function is brutally simple: 1 point if the final answer is an exact match to the reference answer, 0 otherwise. No partial credit, no points for format (unlike DeepSeek's <think> tags).
Why So Simple? They deliberately avoided more complicated reward functions (like process rewards or neural reward models). Their reasoning:
They believed complex rewards were likely unnecessary for their goal.
They had concerns about reward hacking(like in the case of Deepseek).
RL Algorithm Deep Dive: PPO + GAE
ORZ used PPO + GAE(Generalized Advantage Estimation)
Read this for some basics. Feel free to skip if you already know what GAE is.
The "advantage" tells us how much better a specific action was compared to the average action in that situation, considering future rewards. Estimating this accurately involves a bias-variance trade-off:
Monte Carlo: Using the sum of all actual future rewards is unbiased (correct on average) but high variance(noisy due to random outcomes in single episodes).
Temporal Difference(TD): Using the immediate reward plus the estimated value of the next state is low variance (more stable) but potentially biased (if the value estimate is wrong).
How GAE Helps:
GAE blends these approaches. It combines information from multiple time horizons – from 1-step returns (like TD) up to full Monte Carlo returns – using an exponentially decaying weight (λ). Tuning λ allows control over the bias-variance trade-off: λ near 0 favors lower variance (more bias), while λ near 1 favors lower bias (more variance).
GAE Lambda λ = 1.0: This effectively means they didn't blend estimates. Instead, they used the Monte Carlo approach for advantages: calculating the advantage as the actual total future reward minus the value function's baseline estimate (V(s_t)). This is unbiased but high variance.
Discount Factor γ = 1.0: This means no discounting. All rewards in an episode contribute equally to the total return. This emphasizes maximizing the final outcome, aligning with their sparse, final-answer-only reward (1 for correct, 0 otherwise).
No KL Regularization: They achieved stable training without using KL regularization in their loss function! This is quite different from standard RLHF practice, where KL penalties are often considered crucial to keep the model from drifting too far from the base model.
Qwen 2.5
3 stages: SFT → Offline RL(for reasoning, factuality, instruction following)→ Online RL(helpfulness, harmless, truthfulness, relevance, conciseness, debiasing)
Stage 1: SFT
Targeted Enhancement of Core Capabilities:
Reasoning: Boosted mathematical, logical (covering deductive, inductive reasoning, etc.), and structured data reasoning skills. This involved:
Incorporating specialized datasets (e.g., their own Qwen2.5-Math CoT data).
Training on a wide variety of query types.
Using techniques like rejection sampling and reward modeling during data creation to ensure high-quality reasoning examples.
Explicitly training the model to generate clear reasoning chains (Chain-of-Thought) in its outputs.
Coding: Significantly improved coding proficiency across numerous programming languages by using:
Dedicated coding instruction datasets (e.g., Qwen2.5-Coder).
Multi-agent frameworks to generate diverse coding examples.
Synthesized coding problems and solutions.
Rigorous validation using multilingual sandboxes and automated testing frameworks to check code correctness.Data Generation and Quality Control: A major focus was on creating high-quality, diverse SFT data using advanced techniques and strict filtering:
Advanced Data Generation and Quality Control: A major theme was creating high-quality, diverse SFT data with strict filtering:
Addressing Length Limitations: Generated long-response training data (targeting up to 8,000 tokens). They did this by using back-translation on their pre-training data to create relevant long-context queries.
Validation Methods: Ensured data quality and instruction adherence through methods like:
Code-Based Validation: Having LLMs generate verification code or tests alongside the instruction-response pairs.
Execution Feedback: Running generated code or commands to check correctness.
Rigorous Filtering: Implemented extremely strict quality control:
Used multiple automated methods (critic models, multi-agent scoring frameworks) to evaluate potential SFT examples.
Only retained examples deemed flawless by all checking systems.
Employed iterative refinement, especially to filter out examples containing flawed reasoning steps.
Improving Robustness and Generalization: Focused on making the model reliable and ensuring capabilities transfer well:
Cross-Lingual Transfer: Systematically generated SFT data for lower-resource languages. This involved translating English instructions and carefully ensuring the translated instructions aligned semantically with the original responses, effectively transferring capabilities learned from high-resource data.
System Prompt Robustness: Trained the model on hundreds of diverse system prompts to make its performance consistent and less sensitive to variations in how it's instructed.
Large-Scale Implementation: This entire SFT process was massive:
Utilized over 1 million SFT examples.
Trained with a very long sequence length (32,768 tokens), enabling better handling of long contexts right from the SFT stage.
Stage 2: Offline RL - Refining Objective Skills
Offline RL focused on polishing capabilities where clear right/wrong answers exist but might be tricky for simple reward models to evaluate perfectly.
Goal: To further refine objective capabilities like math, coding, reasoning, and instruction following.
Method: Leveraged techniques from the SFT quality-checking pipeline (like execution feedback and answer matching) as part of the reward signal.
Signal Enhancement: Added layers of human review and further automated checks to ensure the reward signals were reliable.
Algorithm & Scale: Used DPO with a dataset of 150,000 preference pairs.
Stage 3: Online RL - Aligning with Subjective Preferences
The final stage shifted focus to more subjective qualities, using Online RL to align the model closely with human preferences for interaction quality.
Goal: To improve helpfulness, harmlessness, truthfulness, relevance, conciseness, and reduce biases.
Algorithm: Employed GRPO
Data Source: Used the same set of queries that were prepared for training their reward models.
Training Strategy: They focused first on queries where the model's responses had high variance in reward scores. The intuition is that these are the queries where the model is most uncertain or inconsistent, offering the biggest opportunity for learning and improvement.
QwQ 32B
A simpler RL-focused approach, notably starting from a cold checkpoint.
RL
Starting Point: Initiated RL directly from a cold-start checkpoint (no preceding SFT like in Deepseek-R1 Zero and OpenReasoner).
Two-Stage Process:
Stage 1 (Math & Coding Focus):
Targeted only math and coding tasks initially.
Used outcome-based rewards (accuracy verifier for math, code execution server), not a learned reward model at this stage.
Stage 2 (General Capabilities Enhancement):
Added a brief subsequent RL phase.
Focused on general skills (instruction following, preference alignment, agent use).
Utilized a mix of rewards: signals from a general learned reward model combined with some rule-based verifiers.
Kimi 1.5
This is a recent reasoning model by Moonshot AI that grabbed a lot of attention.
Stage 1: SFT
Hybrid Data Generation Strategy: Kimi uses different approaches depending on the task type:
Non-Reasoning Tasks (QA, Writing, etc.): Multi-step and human-in-the-loop:
Humans annotated an initial seed dataset.
A seed model was trained on this data.
The seed model generated multiple responses for diverse prompts.
Human annotators then ranked these responses and refined the best one into a high-quality example.
Reasoning Tasks (Math, Coding): Relied more on rejection sampling, leveraging efficient automated verification (rule-based checks or reward models) to filter good reasoning examples.
Comprehensive & Large Dataset: The SFT dataset was extensive:
Compiled approximately 1 million text examples covering various domains (QA, coding, math, writing, long-context).
Included about 1 million text-vision examples involving charts, OCR, visual QA, visual coding, and visual reasoning.
Staged Long-Sequence Training: To handle long contexts effectively, SFT was done progressively:
First Epoch: Trained with a 32k sequence length.
Second Epoch: Increased training to a significantly longer 128k sequence length.
Stage 2: RL
Their meticulous Prompt Set Curation focused on three pillars:
Broad Topic Coverage: To ensure the model could reason across the board, prompts spanned STEM, coding, and general reasoning, including both text-only and image-based questions. They used automatic filtering and detailed tagging to keep the mix balanced.
Balanced Difficulty: Getting the difficulty right is tricky. Kimi's approach was clever: they used their already fine-tuned SFT model to attempt each potential RL prompt multiple times with high randomness. The resulting pass rate gave them a direct measure of how hard that prompt was for their specific model. This allowed them to filter out trivially easy problems and ensure a good mix of easy, medium, and hard challenges tailored to the model's learning stage.
Accurate Evaluation (Fighting Reward Hacking): Knowing if the model truly succeeded is key. Kimi prioritized prompts where both the reasoning steps and the final answer could be reliably checked. They actively excluded fuzzy question types prone to hacking (like multiple-choice or proofs). They even implemented a specific "easy-to-hack" test for QA: if the model could guess the answer correctly within 8 tries without being asked to show its work (no Chain-of-Thought), they tossed the prompt – it didn't truly test reasoning.
Adding a Special Prep Step: "Long-Context SFT" Warmup
Before the main RL phase, Kimi added an interesting "warmup" step. The goal was to proactively equip the model with structured problem-solving strategies like planning, evaluation, reflection, and exploration.
How they did it: Starting with their carefully curated RL prompts, they used advanced prompting techniques to guide a model to generate long, detailed Chain-of-Thought (CoT) reasoning paths (for both text and image inputs). They then created a small but very high-quality SFT dataset containing only these verified, long CoT examples demonstrating the desired cognitive processes. Finally, they performed a lightweight SFT just on this specialized dataset. Think of it as giving the model a reasoning toolkit before asking it to optimize its performance via RL.
Curating Vision Data for RL
To make the model genuinely useful with images, their Vision RL data came from diverse sources:
Real-world Data: Included science questions needing graph interpretation, location guessing tasks from images, and chart analysis problems – grounding the model in practical visual tasks.
Synthetic Visual Reasoning Data: They generated artificial images and scenes designed to hone specific skills like understanding spatial relationships or geometric patterns, offering controlled tests and endless examples.
Text-Rendered Data: To ensure consistency, they converted text documents, code snippets, etc., into images (like screenshots). This trained the model to respond similarly whether it saw plain text or text within an image.
Key Learnings in the Kimi RL Training Process
Kimi incorporated several interesting details into the RL training itself:
The Reward Signal: At its core, the reward (r) was kept relatively simple: binary (0 or 1) based only on whether the final answer was correct.
Verification: For verifiable problems (like coding), rule-based checks (e.g., code execution via auto-generated test cases) were used. They even built a sophisticated system using their base model and the CYaRon library to automatically generate and validate test cases for coding problems lacking them.
Improving Math Rewards: Recognizing that math answers can have equivalent forms (e.g., a² - 4 vs (a+2)(a-2)), they compared two reward model approaches: a standard "Classic RM" and a "Chain-of-Thought RM" that generated reasoning before judging. The CoT RM proved significantly more accurate (98.5% vs 84.4%) and was adopted for RL training, ensuring more reliable feedback.
Sampling Strategies: They didn't just feed prompts randomly; they used smart sampling to make training more efficient:
Curriculum Sampling (Easy First): They started the RL process with easier problems, identified using existing difficulty labels (like grade levels), and only gradually introduced harder ones. It's interesting to contrast this with Qwen 2.5's strategy in their online RL phase (which we saw earlier), where they opted to initially prioritize prompts showing high reward variance – tackling the areas of highest uncertainty(hard prompts) first. Kimi's approach focuses on building foundational skills progressively before hitting the really tough stuff.
Prioritized Sampling (Focus on Weak Spots): During training, they tracked the model's success rate on each specific problem. Problems the model frequently got wrong were sampled much more often (probability proportional to the failure rate 1 - sᵢ). This dynamically focused training effort on the areas where the model needed the most improvement.
Tackling "Overthinking" with a Length Penalty: Like many RL-trained models, Kimi tended to produce overly long responses. To counter this, they added a length penalty to the reward. Correct answers got a slight bonus if short, a penalty if long. Incorrect long answers got penalized even more heavily. This penalty was introduced gradually ("warmed up") so it didn't stifle learning in the early stages.
Long2short
While the long-CoT models were powerful, they used a lot of tokens at inference time. Kimi explored several techniques to transfer the reasoning prowess of these models into more efficient "short-CoT" versions:
Model Merging: Simply averaged the weights of a trained long-CoT model and a short-CoT model.
Shortest Rejection Sampling (for SFT): Generated multiple answers from the long-CoT model, selected the shortest correct one, and used it for SFT data.
DPO: Created preference pairs where the shortest correct answer was 'chosen', and longer answers (both incorrect ones and correct ones significantly longer) were 'rejected'.
Long2short RL: Ran a separate RL phase specifically applying the length penalty more aggressively to train for conciseness.
Phi 4
Microsoft's Phi-4 post-training involved an SFT phase followed by two distinct rounds of Direct Preference Optimization (DPO) for its RL component.
Stage 1: SFT
Before diving into preference tuning, Phi-4 went through a comprehensive SFT stage:
Broad Scope: The SFT data covered a wide range of tasks and domains, including math, coding, reasoning, general conversation, defining the model's identity, and crucial safety alignment.
Going Multilingual: They explicitly added multilingual data covering 40 languages to broaden its linguistic reach.
This SFT phase involved a hefty amount of data – around 8 billion tokens.
Stage 2: RL
After SFT laid the foundation, Phi-4 used DPO in two sequential rounds:
Improvements Targeted: The overall goal of the RL phase was to enhance math, coding, reasoning capabilities, improve general robustness, and support safety measures.
Round 1 DPO :
Preference Data Generation (Pivotal Token Search - PTS): This round used a technique called Pivotal Token Search (PTS) to create the preference pairs needed for DPO.
How PTS Works (Intuitively): Instead of comparing entire good vs. bad answers, PTS zeroes in on the single most crucial token choices within a response. It identifies specific "pivotal tokens" where choosing that one token drastically changes the odds of the final answer being correct. DPO then learns from targeted pairs comparing just one good next token versus one bad next token after the same preceding text. This concentrates the learning signal directly on these critical decision points in the generation process.
Data Focus: The data used for this PTS-based DPO round covered chat formats, reasoning tasks, and Responsible AI (RAI) safety data.
Round 2 DPO (Judge-Guided DPO):
Scale: This round involved a much larger dataset, gathering approximately 850,000 preference pairs.
Prompt Sources: Drew prompts from diverse public instruction tuning datasets, supplemented with specific safety/RAI prompts.
Response Generation (Mixing Models): To create the candidate responses for comparison, they used multiple models: GPT-4o, GPT-4 Turbo, and their own Phi-4 SFT model.
Note that responses forming the preference pairs come from different models here, including GPT-4o and GPT-4 Turbo. This differs from the common DPO practice where both preferred and rejected responses usually stem from the same distribution as the model we want to do DPO on. However, in this context, using responses from GPT-4 models makes sense, as GPT-4 is the teacher model for Phi-4.
GPT-4o as RM: They used GPT-4o as a judge to evaluate the generated response pairs and determine which one was preferred.
Judging Criteria: The GPT-4o judge assigned scores and made preference decisions based on accuracy, style, and detail.
🎯 Key Takeaways and Reflections on Post-Training Pipelines
Exploring the diverse post-training pipelines across models like Kimi, Qwen, DeepSeek, OpenReasoner, QwQ 32B, and Phi-4 reveals how differently each team addresses reasoning and alignment.
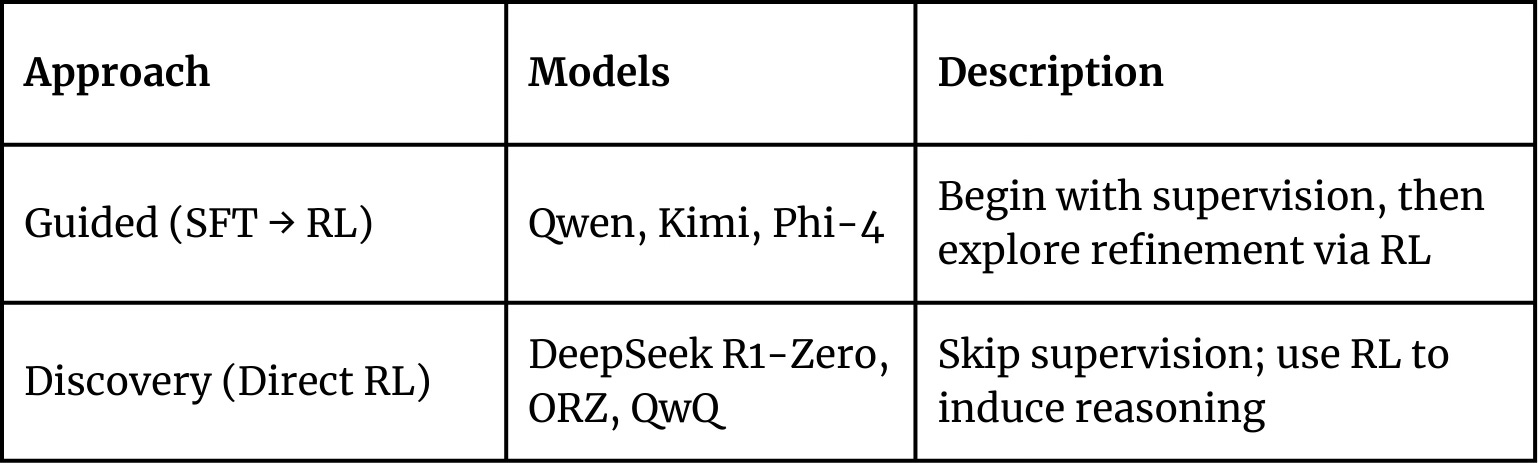
Different Starting Points: SFT vs. Direct RL
Models broadly fall into two camps regarding initial training approaches:
The Guided Approach: Teams behind Qwen, Kimi, and Phi-4 start with supervised fine-tuning before unleashing RL. It's like providing a foundation of examples – some human-written, others AI-generated – before letting the model learn through trial and error. This deliberate first step helps establish core behaviors from the beginning.
The Discovery Approach: DeepSeek R1-Zero, OpenReasoner-Zero, and QwQ 32B boldly skip straight to RL with carefully designed reward systems. This streamlined approach led to fascinating surprises, like DeepSeek's model spontaneously developing reflection and verification skills nobody explicitly taught it – pure learning through experience.

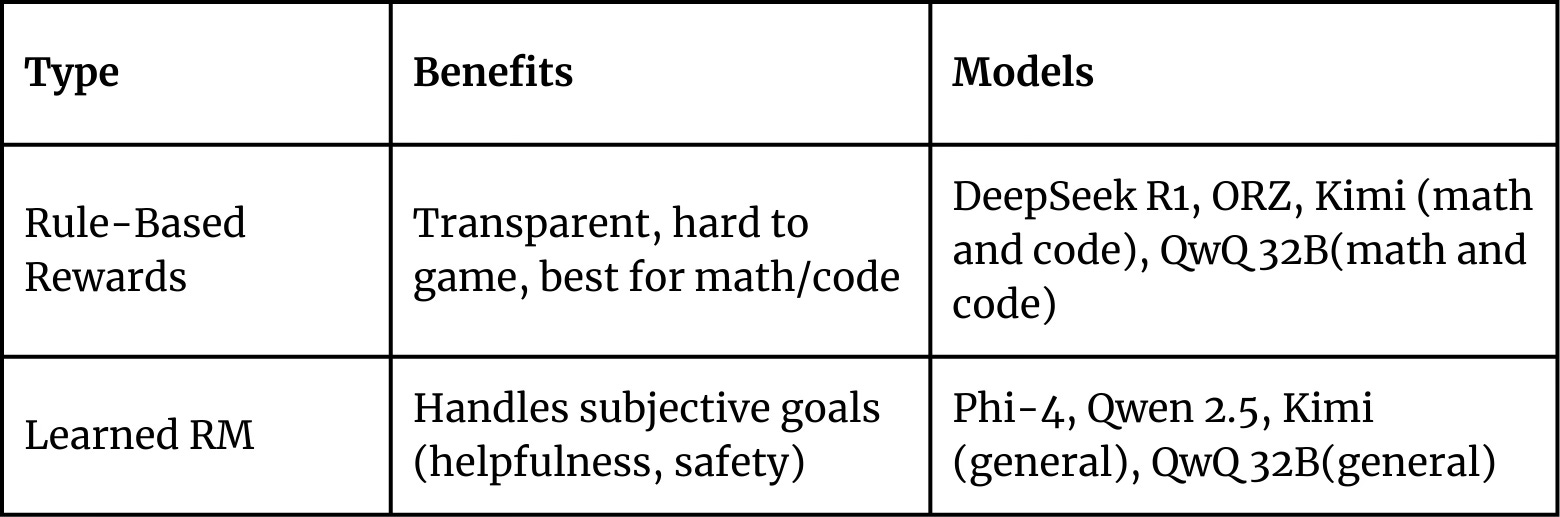
The Reward Modeling Debate: Transparency vs. Flexibility
Rule-Based Rewards: DeepSeek, OpenReasoner, and others embrace simple, rule-based reward systems that are crystal-clear: get the math right, format your code properly, stick to English. These transparent systems are nearly impossible for models to game and make debugging straightforward. They work beautifully for objective tasks but struggle with subjective qualities like "Is this response helpful?" or "Could this be harmful?"
Learned Reward Models: Phi-4, and Qwen instead rely on sophisticated learned reward models that capture nuanced human preferences. These can evaluate subtle qualities like helpfulness and harmlessness, these can evaluate subtle qualities like helpfulness and harmlessness and any tasks where success can't be verified by simple rules. The tradeoff? Less transparency and the risk that models might learn to please the reward system rather than genuinely improve.
Kimi blends interpretability and nuance with a Chain-of-Thought reward model—reasoning before judging—to reach 98.5% accuracy in math evals.
Data Curation: Verifiability and Difficulty Filters
Okay, algorithms aside, digging into how these teams handle data reveals a ton. Even with different starting points or reward philosophies, some core lessons seem universal when it comes to data:
Quality Over Quantity, Period: Forget just vacuuming up data. Everyone from Qwen (with their intense "flawless" filtering) to Kimi and DeepSeek (using sharp human and AI checks) agrees: better data, even if less of it, leads to better models. It's the ultimate "garbage in, garbage out" scenario.
Mastering the Difficulty Curve: How hard is too hard? Teams aren't just guessing. They're actively measuring difficulty, often using their own models (like Kimi testing prompts on its SFT version, or ORZ using a filter model) to estimate pass rates relative to the model's current ability. This allows them to filter out the trivially easy problems and the seemingly impossible ones. But it goes beyond simple filtering; it extends to actively shaping the learning trajectory through techniques like curriculum learning (starting easier, like Kimi) or strategically focusing on the toughest nuts to crack (like ORZ's hard prompt mining or Kimi's prioritized sampling of failed problems). It’s about optimizing the learning gradient.
Verifiability is King: There's a clear trend towards problems where success is undeniable – where it's obvious if the model nailed it. Math problems with clear answers, code that compiles and passes tests. This focus arises because a clean, reliable reward signal is crucial for effective RL. Kimi's "anti-hacking" checks drive this home; the goal is to reward models that reason, not just guess well. Ultimately, what can be reliably measured shapes what the model learns to do.
Notable Innovations
Several technical innovations stand out across these pipelines:
Innovations in Data Curation & Selection:
Qwen's extreme quality filtering system: Setting a high bar by rejecting any SFT examples not deemed "flawless" by multiple verification methods.
Kimi's Model-Based Difficulty Assessment & Anti-Hacking Filter: Using the model itself to gauge prompt difficulty and actively filtering out guessable problems to ensure true reasoning is rewarded during RL.
OpenReasoner Zero's Hard Prompt Mining: Strategically identifying and concentrating final RL training steps exclusively on the most difficult problems for the model.
Qwen 2.5's prioritization of high-variance queries: Efficiently focusing online RL efforts on prompts where the model shows the most uncertainty or inconsistency.
Innovations in Training Setup & Strategy:
Kimi's Long-Context SFT Warmup: A dedicated preparatory SFT stage before RL, specifically designed to instill structured problem-solving patterns (planning, reflection).
OpenReasoner-Zero's training without KL regularization: Challenging conventional RLHF wisdom by achieving stable training without the typical KL penalty to prevent divergence.
Innovations in Reward Modeling:
Kimi’s Chain-of-Thought RM: Dramatically improving reward accuracy (especially for math) by having the reward model generate reasoning before scoring.
DeepSeek-R1's Language Consistency Reward: Introducing a specific reward component during RL explicitly designed to tackle language mixing in multilingual outputs.
Innovations in RL Algorithms & Optimization:
Phi-4's Pivotal Token Search (PTS): Refining DPO by focusing the optimization pressure on the single most critical token choices within a generation.
Kimi's Long2Short optimization: Developing techniques (merging, sampling, DPO, RL penalty) to transfer reasoning from verbose models to more efficient, concise ones post-training.
Conclusion
Phew, that was a lot of information! From DeepSeek's zero-shot RL approach that lets reasoning behaviors emerge naturally, to Qwen's meticulously staged progression, to Kimi's innovative Chain-of-Thought reward modeling—we've seen fascinating diversity in how teams transform pretrained models into reasoning powerhouses.
Whether you're training your own models, evaluating research trends, or just curious about how reasoning emerges in LLMs, I hope this deep dive clarified the vast post-training landscape. Please let me know your feedback/ comments below. Thank you so much for reading!